注意
この文書は2007/6/22に書かれたもので、ソフトウエアの名称、バージョン、設定項目、社名などの固有名詞などなどは当時のまま掲載しています。
ですので、インストール手順や設定内容は最新版のドキュメントを参照していただき、この文書からは理論や考え方、構成のヒントなどを読み取っていただければと思います。
はじめに
前回は、HTTP以外のサービスをロードバランスしたり、ロードバランサを内側にも置いたりしてみましょう、といったお話をしました。前々号の特集でもIPVSを使ったLinuxロードバランサの記事をお届けしたので、ロードバランサについてはちょっと食傷気味なんじゃないかと思います。
そこで今回はロードバランサからは離れて、耐障害性が高いストレージサーバをLinuxでこしらえてみたいと思います。
今回お届けする内容は、データを預かるストレージサービスのバックエンドをはじめ、社内のファイルサーバなどでも活用できるのではないかと思います。
こんなストレージサーバが欲しい!
今回はこんなストレージサーバを考えてみます。
- ストレージサーバへの読み書きにはNFSを使う。
- 動画や画像や音といったような、一つのファイルサイズが比較的大きいのを格納したい。
- 格納したいファイルが大量にある。
最近はハードディスクのバイト単価がかなり安くなってきていますし、単体で1TBを越えるSATAのハードディスクも市場に出回っています。ですので、Linuxでこの要件を満たすストレージサーバを作るなら、大きめのハードディスクを入れてNFSサーバとなるのに必要なデーモン(常駐プロセス)を起動するだけで完成してしまいます。
消えてしまってもいいデータを格納するならばこれだけでもいいのですが、再生成不可能なオリジナルなメディアデータを格納するには、やっぱり故障に強いストレージサーバが欲しくなりますよね。ということで少し考えてみましょう。
データがなくならない
さて、故障からデータを守るというと、まず思い浮かぶのはRAIDではないでしょうか。確かに、RAIDはストレージサーバには必須ともいえるのですが、RAIDは万能かというとそうではありません。例えば、RAID 1やRAID 5の場合は、ディスクが同時に2台壊れると(注1)データが失われてしまいます。
では、別のディスクにバックアップをとればいいのではないか、ということになると思うのですが、領域全体のサイズが大きいとフルバックアップをとるのにかなりの時間がかかりますし、差分バックアップをとるにもファイルの数が非常に多いと、差分を確認するフェーズにかなりの時間がかかるようになってしまいます。バックアップ中は負荷もかかるので、このような状況になると、サービスに影響なくバックアップをとるということが困難になってきます。
また、このような定期バックアップの場合、最後にバックアップしてからの時間がたてばたつほど、バックアップと本データが乖離してしまうという問題もあります。
ディスクが1台壊れたのでスペアディスクを投入したら、実はそのスペアディスクも壊れていたなんてことが起こるとかなり心拍数が上がります。
サービスがとまらない
プロダクション環境の場合は、データがなくならないということのほかに、ストレージサービスが止まらない、というのも重要な要件に入ってきます。
RAID構成にすれば、確かにディスクが故障してもサービスは継続できるのですが、これ以外のケース、例えば、
- RAIDコントローラが壊れた
- RAIDと関係ない部分(電源やメモリなど)が壊れた
場合はストレージサーバのサービスは止まってしまいます。
また、復旧時にデータをバックアップから戻す場合、数百GBのデータをバックアップからコピーするとなると、それなりの時間を要するので、サービスの復旧が完了するまでの時間が長くなってしまいます。
なんかいい方法はないの?
ここまででみたように、データの保全とサービスの可用性を両立するとなると結構難しいのですが、Linuxにはいいものがあります。それはDRBDです。
DRBDとは?
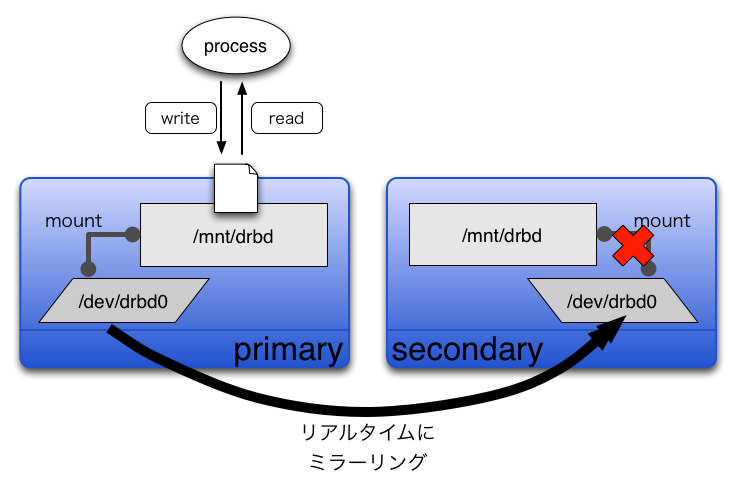
DRBD(Distributed Replicated Block Device)(注2)とは、おおざっぱにいうと、ネットワーク越しのミラーリングです。RAID 1がローカルバスを介したディスク対ディスクのミラーリングであるように、DRBDはネットワークを介したサーバ対サーバのミラーリングです(図1)。
OSからみると、DRBDはその名のとおり、通常のハードディスク(/dev/hdaや/dev/sda)と同じようにブロックデバイスに見えるので、mkfsコマンドでお好みのファイルシステムを作って、mountして使います。
一連のミラーリングはブロックデバイスより下のレイヤで行われるため、使う側は、DRBDデバイスか物理ディスクのデバイスかの違いを意識せず、まったく同じようにファイルを作ったり消したりすることができます。
このDRBDを使うことにより、先ほど出てきた2つの問題点:
- データの保全 →リアルタイムに別サーバにミラーリングする。
- 可用性 →プライマリサーバが故障した場合は、セカンダリサーバをプライマリに昇格すればいいのでダウンタイムを短くすることができる。
を解消することができます。
さて、こうなってくると、セカンダリサーバをたくさんぶらさげて読み出しを分散させたくなってきますが、残念ながら現行のDRBDではできません。その理由はこうです。第一に、DRBDは必ずプライマリとセカンダリの2台で構成しなければなりません(注3)。第二に、セカンダリのブロックデバイスは読み出し限定のアクセスはおろか、mountすらできません(注4)。
ただし、DRBD 8.xとOCFS2(Oracle Cluster File System)もしくはGFS(Global File System)を併用すれば、プライマリ/プライマリの構成をとれるようです。
フェイルオーバはどうするか?
DRBDによってデータの保全と可用性を高めることはできそうなのがわかったところで、次にフェイルオーバについて考えてみましょう。
DRBDそのものには自動的なフェイルオーバの機能はなく、フェイルオーバする際にはいくつかの管理コマンドを実行する必要があります。ですので、プライマリとセカンダリの両方で監視プログラムを動かして、状態が変化したら、適宜、DRBDの管理コマンドを実行してプライマリに昇格させる必要があります。
ですので、プライマリとセカンダリの両方で監視プログラムを動かして、状態が変化したら、適宜、DRBDの管理コマンドを実行してプライマリに昇格させたりする必要があります。
また、フェイルオーバした際に、プライマリサーバのIPアドレスが変わってしまうと、クライアントはNFSマウントし直す必要がありめんどうです。なので、サービス用のIPアドレスは浮動する仮想IPアドレスとし、常にプライマリがこのIPアドレスを持つようにします。そして、クライアントはこの仮想IPアドレスに対して、NFSマウントのリクエストをするようにします。
さて、このへんの監視、フェイルオーバの仕組みをゼロから作り上げてもよいのですが、今回はフレームワークとしてkeepalivedを使ってみたいと思います。
keepalivedには2つの機能1. IPVSによるロードバランスと、リアルサーバの死活監視2. VRRPによるアクティブ/バックアップ構成の冗長化があるのですが、それぞれの機能を個別に独立して使うこともできます。今回は2のVRRPの機能だけを使います。
VRRPは元々ルータの冗長化のために考案されたプロトコルなのですが、2つ以上のノードでグループを作り、その中の1つだけがマスタとなり何かしらのサービスを提供するような用途であれば、ルータに限らず活用できるすぐれものです。グループ内のネットワーク的な疎通監視や、仮想IPアドレスの割り当て(注5)はVRRPがやってくれるので、監視プログラムではそのあたりのコードを書く必要はありません。
外部プログラムによるサービス監視が失敗した場合は、keepalivedを再起動すればフェイルオーバを起こせます。
また、keepalivedは、VRRPの状態の変化をフックして任意のプログラムを実行することができるので、ここでDRBDの管理コマンドを実行すればよさそうです。
一般的に、IPアドレスがほかのノードに移動した場合、ネットワーク機器やサーバのarpテーブルのキャッシュが消えるまで、つまり新しいノードのMACアドレスとIPアドレスが正しく関係付けられるまでは新しいノードと通信できません。 一般的なVRRPの場合はMACアドレスも移動させることでこの問題を解消しています。 しかしkeepalivedのVRRPの実装は仮想MACアドレスには対応していません。恐らく、Linuxでは1つのNICに複数のMACアドレスをつけられないためだと思います。では、keepalivedはどうしているかというと、Gratuitous ARPというパケットを投げています。Gratuitous ARPを送ることにより、他のノードのARPキャッシュのエントリを更新することができるのです。 ここでは詳細は割愛しますが、Gratuitous ARPについては、RFC 3344の「4.6. ARP, Proxy ARP, and Gratuitous ARP」などを参照するとよいでしょう。
ここまでのまとめ
ここまでをまとめるとこうなります。
要件
- ストレージサーバを作る。
- たくさんのファイルを格納する。
- ひとつのファイルのサイズは数MB〜数十MB。
- 領域全体のサイズは数百GB。
問題
- データの保全
- 領域全体が大きいので、フルバックアップには時間がかかる。
- ファイルが多いので、差分バックアップも時間がかかる。
- 定期バックアップはリアルタイム性がないので、復旧時に欠損データが発生する可能性がある。
- 可用性
- ディスクはRAIDで冗長化できるが、RAID以外の部分の故障には弱い。
- 領域全体が大きいので、バックアップがあっても復旧時のデータコピーに時間がかかる。
解決策
- データの保全 → DRBDでリアルタイムに別サーバにミラーリングをする。
- 可用性 → keepalivedのVRRPの機能+補助プログラムで、死活監視とフェイルオーバを行う。
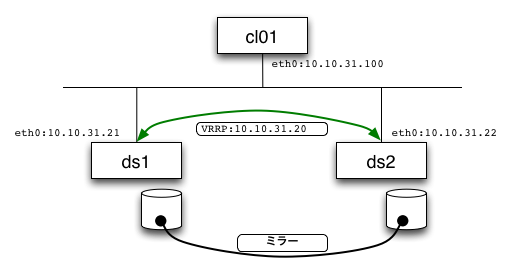
構成は図2のようになります。次節からは、実際に作るステップを紹介していきます。
構築環境
今回、使う環境は以下の通りです。
- Debian/GNU Linux 3.1 (sarge)
- kernel 2.6.18.8 (ソースからコンパイル)
- nfs-common 1.0.6-3.1
- nfs-kernel-server 1.0.6-3.1
- drbd 0.7.23 (ソースからコンパイル)
- keepalived 1.1.13 (ソースからコンパイル)
ソースからコンパイルするものは、ディストリビューションのパッケージがインストールされていないか確認して、インストールされているものがあったら、当該パッケージはアンインストールしたほうがよいでしょう。
DRBDでネットワーク越しのミラーリング
DRBDのインストール
DRBDの最新の安定版は8.0系なのですが、安定版になったのが2007/01/24とまだ日が浅いので、今回は0.7系の最新(0.7.23)を使います。
DRBDはkernelモジュールです。よって、導入するのにkernelにパッチを当てる必要はありませんが、コンパイルするためにkernelのソースツリーが必要です。
はじめてDRBDを導入する場合は、図3のようにします。これで、
- /sbin/drbdsetup, /sbin/drbdadm
- /etc/init.d/drbd
- /etc/drbd.conf
- /lib/modules/KERNEL_VERSION/kernel/drivers/block/drbd.ko
といったファイルがインストールされます。
もし、kernelモジュールのみインストールしたい場合は、図fn_install_drbdkoのように、「drbd」というサブディレクトリでmake installを実行します。
$ wget http://oss.linbit.com/drbd/0.7/drbd-0.7.23.tar.gz $ tar zxf drbd-0.7.23.tar.gz $ cd drbd-0.7.23 $ make # make install # update-rc.d drbd defaults
$ cd drbd-0.7.23/drbd $ make # make install
DRBDの設定
今回は、2台のサーバ(ds1とds2)のディスク/dev/sdb1をDRBDでミラーリングして/dev/drbd0という名前のデバイスでアクセスできるようにしてみます。
まずはds1とds2のそれぞれで、fdiskなどで/dev/sdbにパーティション(sdb1)を作ります。
続いて、DRBD用のデバイスファイルを作ります。ds1とds2のそれぞれで、図5を実行します。
# for i in `seq 0 15` ; do mknod /dev/drbd$i b 147 $i; done
次にDRBDの設定ファイルを作ります。リストlist_drbdconf0の内容のファイルを/etc/drbd.confに配置します。
重要な設定項目をいくつか解説します。完全な説明はman drbd.confを参照してください。
DRBDはプログレスバーがある対話的なダイアログを出すことがあるのですが、(1)のdialog-refreshはその描写間隔(秒)を指定します。0を指定した場合は再描写しないようになります。シリアルコンソールの場合、再描写がかかると画面が乱れることがあるので、ここでは0を指定して再描写しないようにしています。
- のresourceではじまるブロックは、DRBDデバイスの設定をします。今回は、設定するDRBDデバイスは1つですが、複数ある場合はそれに応じてresourceブロックも複数書きます。
- のprotocolは、どこまで書き込めば「書き込み完了」とみなすかを指定する項目です。指定可能な値であるA、B、Cの説明を表1にまとめます。Aがもっとも書き込み性能がよいですが、反面、もっとも信頼性が低くなります。
- のon-io-errorは、ディスク故障などで物理ディスクからIOエラーが出たときの動作を指定します。panicを指定した場合、kernel panicになりサーバは停止します。ほかにpass_onとdetachが指定できるのですが、detachはちょっと注意が必要です。detachの場合はIOエラーが起こるとデバイスを切り放すのですが、同時にセカンダリにNegRSDReplyというDRBDのパケットを送ります。そして、それを受け取ったセカンダリはkernel panicする実装になっています。つまり、detachの場合はDRBDのノードは全滅してしまいます。フェイルオーバしたい場合は、このようなdetachの動作は好ましくないので、今回はpanicを指定します。
onではじまるブロックが、(5)-1と(5)-2の2つあります。ここで、DRBDを構成するノードを定義しています。onのあとには、それぞれのノードの名前を指定します。この名前はuname -nの結果と一致している必要があるので注意してください。
このonブロックの中では、DRBDのデバイス(device)や物理デバイス(disk)やノード同士が通信するためのIPアドレスとポート(address)を指定します。resouceが複数ある場合は、それぞれdeviceとdiskとaddressのポートは別なものにする必要があります。deviceとdiskはともかく、addressのポート番号は変えるのを忘れやすいので注意しましょう。
最後のmeta-diskは、DRBDの管理領域の場所を指定するものです。管理領域には128MB必要です。internalを指定した場合は、diskで指定した物理ディスクのパーティションの中の128MBが管理領域として使われます。したがって、512MBのパーティションの場合は、128MBを引いた384MBがデータ領域として使えます。internalの他に、「meta-disk /dev/sdb2[0]」のように管理領域専用のパーティションを指定することもできます。
global {
dialog-refresh 0; ────────────(1)
}
resource r0 { ───────────────(2)
protocol A; ───────────────(3)
incon-degr-cmd "echo '!DRBD! pri on incon-degr' | wall";
startup {
wfc-timeout 1;
degr-wfc-timeout 10;
}
disk {
on-io-error panic; ─────────(4)
}
net {
}
syncer {
rate 10M;
group 1;
al-extents 257;
}
on ds1 {─────────────────(5)-1
device /dev/drbd0;
disk /dev/sdb1;
address 10.10.31.21:7788;
meta-disk internal;
}
on ds2 {─────────────────(5)-2
device /dev/drbd0;
disk /dev/sdb1;
address 10.10.31.22:7788;
meta-disk internal;
}
}
| protocol | 書き込み完了になるタイミング |
|---|---|
| A | ローカルディスクに書いて、ローカルのTCP送信バッファに書いたら |
| B | ローカルディスクに書いて、リモートのバッファキャッシュに書いたら |
| C | ローカルディスクに書いて、リモートのディスクに書いたら |
DRBDを使ってみる
ではいよいよDRBDを使ってみましょう。
まずはds1でmodprobeを使いkernelモジュールをインストールします。うまくいけば、/proc/drbdでDRBDの状態が確認できるようになります。続いてdrbdadm up allと実行すると、drbd.confで設定したデバイスが有効になります(図6)。もし途中で失敗したら、drbdadm down allで停止し、失敗原因を直して再度up allを実行します。
ds1# modprobe drbd
ds1# lsmod | grep drbd
drbd 139632 0
ds1# cat /proc/drbd
version: 0.7.23 (api:79/proto:74)
SVN Revision: 2686 build by hirose@ds1, 2007-04-18 11:56:32
0: cs:Unconfigured
ds1# drbdadm up all
ds1# cat /proc/drbd
version: 0.7.23 (api:79/proto:74)
SVN Revision: 2686 build by hirose@ds1, 2007-04-18 11:56:32
0: cs:WFConnection st:Secondary/Unknown ld:Inconsistent
ns:0 nr:0 dw:0 dr:0 al:0 bm:82 lo:0 pe:0 ua:0 ap:0
同じようにds2でも実行してみましょう。すると図7のように、接続状況を示すcs(connection state)の欄がWFConnectionからConnectedに変わり、役割状態を示すst(state)もSecondary/UnknownからSecondary/Secondaryに変わりました。また、dmesgコマンドでDRBDのメッセージを確認することができます。
ds1# cat /proc/drbd
version: 0.7.23 (api:79/proto:74)
SVN Revision: 2686 build by hirose@ds1, 2007-04-18 11:56:32
0: cs:Connected st:Secondary/Secondary ld:Inconsistent
ns:264 nr:0 dw:0 dr:264 al:0 bm:2 lo:0 pe:0 ua:0 ap:0
これで、2つのノードが接続し、両方セカンダリ状態になったので、どちらか片方をプライマリ状態へ移行できるようになりました。プライマリに昇格するにはprimary allと指示します(図8)。
ds1# drbdadm primary all
ioctl(,SET_STATE,) failed: Input/output error
Local replica is inconsistent (--do-what-I-say ?)
Command 'drbdsetup /dev/drbd0 primary' terminated with exit code 21
Broadcast Message from root@ds1
(/dev/pts/2) at 13:19 ...
!DRBD! pri on incon-degr
おっと。エラーが出ました。これは、ローカルディスクの同期が取れていない状態でprimary allを実行すると出るエラーです。同期がとれているかどうかは、/proc/drbdのld(local data consistentency)をみればわかります。
primary allを実行すると、自分が同期元となり相手のデータが書き変わります。したがって、自分のローカルデータの同期が取れていない場合(Inconsistent)は、食い違ったデータで同期しないように、このような防止策がかけられているわけです。
しかし、今回は最初のセットアップなので、同期がとれていないのは当然です。このような場合に、強制的に自分がプライマリになるには、--do-what-I-sayというオプションを合わせて指定します(図9)。これで同期が始まります。ds1とds2の/proc/drbdを見ると、プログレスバーが伸びていくのが確認できます。また、csの値が、同期元のds1は「SyncSource」に、同期先のds2は「SyncTarget」になっているのが確認できるでしょう。しばらく待つと同期が完了し、csの値が「Connected」になります。
なお、csやstの値の種類と解説は、DRBD/FAQ(注6)にありますので、詳しくはそちらを参照してください。
ds1# drbdadm -- --do-what-I-say primary all
ds1# cat /proc/drbd
version: 0.7.23 (api:79/proto:74)
SVN Revision: 2686 build by hirose@ds1, 2007-04-18 11:56:32
0: cs:SyncSource st:Primary/Secondary ld:Consistent
ns:155328 nr:0 dw:0 dr:156352 al:0 bm:91 lo:256 pe:0 ua:256 ap:0
[====>...............] sync'ed: 23.5% (508208/663536)K
finish: 0:10:35 speed: 788 (5,356) K/sec
ds2# cat /proc/drbd
version: 0.7.23 (api:79/proto:74)
SVN Revision: 2686 build by hirose@ds1, 2007-04-18 11:56:32
0: cs:SyncTarget st:Secondary/Primary ld:Inconsistent
ns:0 nr:183396 dw:183396 dr:0 al:0 bm:93 lo:0 pe:256 ua:0 ap:0
[=====>..............] sync'ed: 27.8% (480140/663536)K
finish: 0:04:00 speed: 1,960 (4,264) K/sec
ds1# cat /proc/drbd
version: 0.7.23 (api:79/proto:74)
SVN Revision: 2686 build by hirose@ds1, 2007-04-18 11:56:32
0: cs:Connected st:Primary/Secondary ld:Consistent
ns:663536 nr:0 dw:0 dr:663536 al:0 bm:123 lo:0 pe:0 ua:0 ap:0
同期が完了したら、お好みのファイルシステムを作ってマウントしてみましょう(図10)。
ds1# mkfs -t xfs -f /dev/drbd0 ds1# mkdir /mnt/drbd ds1# mount /dev/drbd0 /mnt/drbd ds1# df -Th /mnt/drbd Filesystem Type Size Used Avail Use% Mounted on /dev/drbd0 xfs 644M 288K 643M 1% /mnt/drbd
DRBDのフェイルオーバを手動で体験
これでDRBDの準備ができたので、フェイルオーバを体験してみましょう。
まずはプライマリ側でファイルを作ります(図11の(1))。
続く図11の(2)からがいよいよフェイルオーバです。まずはアンマウントして、状態をセカンダリに変更します。/proc/drbdを見ると、2台共にセカンダリ状態になっていることが確認できます。
プライマリがいなくなったので、ds2でprimary allを実行してプライマリ状態に変更します。うまくいけば、図のようにstがPrimary/Secondaryに変わります(図11の(3))。
ds2がプライマリになったら、DRBDのデバイスをマウントして、(1)で作ったファイルのタイムスタンプや内容を確認してみましょう(図11の(4))。
DRBDのフェイルオーバのポイントは2つです。1. アンマウントしないとプライマリからセカンダリに変更できない2. 両方ともセカンダリ状態でないとだれもプライマリになれない
(1)
ds1# echo I miss WebDiver > /mnt/drbd/hello_drbd
ds1# ls --full-time /mnt/drbd/
total 4
-rw-rw-r-- 1 root root 16 2007-04-18 13:46:30.074427372 +0900 hello_drbd
(2)
ds1# umount /mnt/drbd
ds1# drbdadm secondary all
ds1# cat /proc/drbd
version: 0.7.23 (api:79/proto:74)
SVN Revision: 2686 build by hirose@ds1, 2007-04-18 11:56:32
0: cs:Connected st:Secondary/Secondary ld:Consistent
ns:2654144 nr:0 dw:69914 dr:2654337 al:21 bm:349 lo:0 pe:0 ua:0 ap:0
ds2# cat /proc/drbd
version: 0.7.23 (api:79/proto:74)
SVN Revision: 2686 build by hirose@ds1, 2007-04-18 11:56:32
0: cs:Connected st:Secondary/Secondary ld:Consistent
ns:0 nr:2060522 dw:2060522 dr:0 al:0 bm:205 lo:0 pe:0 ua:0 ap:0
(3)
ds2# drbdadm primary all
ds2# cat /proc/drbd
version: 0.7.23 (api:79/proto:74)
SVN Revision: 2686 build by hirose@ds1, 2007-04-18 11:56:32
0: cs:Connected st:Primary/Secondary ld:Consistent
ns:0 nr:2060522 dw:2060522 dr:0 al:0 bm:205 lo:0 pe:0 ua:0 ap:0
(4)
ds2# mkdir /mnt/drbd
ds2# mount /dev/drbd0 /mnt/drbd
ds2# ls --full-time /mnt/drbd/
total 4
-rw-rw-r-- 1 root root 16 2007-04-18 13:46:30.074427372 +0900 hello_drbd
ds2# cat /mnt/drbd/hello_drbd
I miss WebDiver
keepalivedでフェイルオーバの自動化
keepalivedとその周辺の設定
keepalivedの設定ファイル
前節では手動でのDRBDのフェイルオーバをやってみました。この節では、keepalivedを使ってDRBDのフェイルオーバを自動化してみましょう。
今回使用するkeepalivedの設定ファイルはリストlist_ka_confのようになります。VRRPだけを使うので、virtual_server_groupやvirtual_serverは必要なく、vrrp_instanceブロックだけです。
さて、keepalivedには、VRRPの状態が変化したタイミングで任意のコマンドやプログラムを実行する機能があります(表2)。
今回は/usr/wd/sbin/dsadmというスクリプトを作り、リストlist_ka_confのように、状態に応じた引数を渡すようにしました。また、notifyで指定した/usr/wd/sbin/save-vrrp-statusは、VRRPの状態をファイルに記録します。
状態変化時に実行するスクリプト
dsadmとsave-vrrp-statusを、それぞれリストlist_dsdmとリストlist_svsに示します。
dsadmはちょっと長いですが特に難しいことはしていません。引数に応じたcase文の分岐があり、その中で実行しているのは先に手動でDRBDのフェイルオーバを行ったときと同じコマンドです。ただ、それに加え、NFSサーバとなるのに必要なデーモンを起動したり停止したりしています。
また、restartのところで/command/svcというコマンドが出てきますが、これはdaemontools(注7)に含まれるコマンドです。daemontoolsについての詳しい説明は割愛しますが、簡単にいうと、デーモンを管理するためのツールで、万が一デーモンが不意に終了してしまっても、daemontoolsが面倒をみて起動し直してくれるという利点があります。
さて、そのdaemontools配下のkeepalivedの起動ファイル(/usr/wd/daemon/vrrp.ds/run)を、リストlist_vrrpdsに示します。
典型的なdaemontoolsのrunスクリプトは、シグナルを受け取るために、起動するデーモンをexecするのですが、今回はリストlist_vrrpdsのようにexecしていません。なぜかというと、execした場合、svc -dで停止するとセカンダリ状態にならない(dsadm backupを実行するタイミングがない)ため、うまくフェイルオーバできないからです。そこで、バックグランドで起動したデーモンのプロセスをwaitし、デーモンプロセスが終了したらdsadm backupを実行してセカンダリ状態になるようにしています。また、シグナルが送られてきたら、trapしてデーモンのプロセスに同じシグナルを送るようにしています。
そのほかの設定
もうちょっと設定ファイルがあります。
NFSで提供するディレクトリを記述した/etc/exportsを用意します(リストlist_exports)。今回は実験のため、rootを匿名ユーザにマッピングするのを抑制するno_root_squashを指定していますが、状況によっては非常に危険なオプションですので、注意してください。
最後にsyslogの設定です。dsadmスクリプトで、ログをsyslogのlocal1というファシリティにとばしているので、このログを/var/log/keepalivedに保存するようにします。sysklogdを使っている場合はリストlist_syslogdを/etc/syslog.confに追加します。
| 設定項目 | 実行されるタイミング |
|---|---|
| notify_master | マスタになったとき |
| notify_backup | バックアップになったとき |
| notify_fault | VRRPを流しているネットワークインターフェースがダウンしたとき |
| notify | 状態が変化したとき全て。notify_XXXの後で実行される。 |
global_defs {
router_id DS
}
vrrp_instance ds {
state BACKUP
interface eth0
garp_master_delay 5
virtual_router_id 20
priority 100
nopreempt
advert_int 1
authentication {
auth_type PASS
auth_pass himitsu
}
virtual_ipaddress {
10.10.31.20/24 dev eth0
}
notify_master "/usr/wd/sbin/dsadm active"
notify_backup "/usr/wd/sbin/dsadm backup"
notify_fault "/usr/wd/sbin/dsadm backup"
notify "/usr/wd/sbin/save-vrrp-status"
}
#!/bin/sh
SYSTEMNAME=$(hostname -s)
DRBDRESOURCE=all
DRBDDEV=('/dev/drbd0')
DRBDMOUNT=('/mnt/drbd')
LOGFILE=/var/log/dsadm
exec 3>&1 4>&2 >>${LOGFILE} 2>&1
log() {
TS=$(echo|/command/tai64n|/command/tai64nlocal)
echo "$TS $@" | logger -t DSADM -p local1.info
}
_send_mail() {
from="$1"; shift
to="$1"; shift
subject="$1"; shift
{
echo "From: $from"
echo "To: $to"
echo "Subject: $subject"
echo
echo|/command/tai64n|/command/tai64nlocal
cat -
} | /usr/sbin/qmail-inject -A -f${from} ${@+"$@"}
}
send_emerg() {
from='scramble-emerg'
to='admin-ktai@example.org, syslog@example.org'
subject="$1"; shift
subject="EMERG $subject"
cat - | _send_mail "$from" "$to" "$subject" ${@+"$@"}
}
send_warn() {
from='scramble-warn'
to='admin-ktai@example.org, syslog@example.org'
subject="$1"; shift
cat - | _send_mail "$from" "$to" "$subject" ${@+"$@"}
}
send_info() {
from='scramble-info'
to='syslog@example.org'
subject="$1"; shift
cat - | _send_mail "$from" "$to" "$subject" ${@+"$@"}
}
exist_lock_file() {
[ $# -eq 2 ] || return 1
LOCKFILE=$1
EXPIRE=$2 # min
find $LOCKFILE -mmin +0 -exec rm {} \; > /dev/null 2>&1
[ -f $LOCKFILE ] && return 0
touch -d "$EXPIRE min" $LOCKFILE
chmod 666 $LOCKFILE
return 1
}
[ "$1" != 'status' ] && log "BEGIN $@"
case "$1" in
active|backup|restart)
if [ "0" != `id -u` ];then
exec 1>&3 2>&4
echo "[ERROR] you must be root." 1>&1
exit 1
fi
;;
esac
case "$1" in
########################################################################
active)
echo "$SYSTEMNAME try to become primary." | \
send_info "$SYSTEMNAME TRY TO BECOME PRIMARY"
try=30
LOCKFILE=/tmp/.dsadm
while true; do
log "${try}: primary ${DRBDRESOURCE}"
drbdadm -- --do-what-I-say primary ${DRBDRESOURCE} && break
let "--try" || {
if $(exist_lock_file $LOCKFILE 5); then
:
else
{
echo "$SYSTEMNAME cannot become primary."
echo '[HOWTO]'
echo '"drbdadm secondary all" at another server.'
echo '"drbdadm primary all" at this server.'
echo 'if failed, "drbdadm -- --do-what-I-say primary all" at this server.'
} | send_emerg "$SYSTEMNAME FAILED DRBD PRIMARY"
fi
exit 20
}
sleep 1
done
i=0
while [ $i -lt ${#DRBDDEV[@]} ]; do
log "mount ${DRBDDEV[$i]} ${DRBDMOUNT[$i]} ..."
mount ${DRBDDEV[$i]} ${DRBDMOUNT[$i]}
if [ $? -ne 0 ]; then
log "cannot mount ${DRBDDEV[$i]} ${DRBDMOUNT[$i]}"
{
echo "$SYSTEMNAME cannot mount ${DRBDDEV[$i]} ${DRBDMOUNT[$i]}"
echo '[ORDER]'
echo 'need to mkfs?'
} | send_emerg "$SYSTEMNAME FAILED MOUNT DRBD DEVICE"
fi
i=$(($i+1))
done
[ -e /var/lib/nfs/rmtab ] || touch /var/lib/nfs/rmtab
/etc/init.d/portmap restart >/dev/null 2>&1
/etc/init.d/nfs-common start
/etc/init.d/nfs-kernel-server start
;;
########################################################################
backup)
/etc/init.d/nfs-kernel-server stop
/etc/init.d/nfs-common stop
/etc/init.d/portmap restart >/dev/null 2>&1
sync && sync && sync
i=0
while [ $i -lt ${#DRBDDEV[@]} ]; do
log "umount ${DRBDMOUNT[$i]} ..."
umount ${DRBDMOUNT[$i]}
i=$(($i+1))
done
drbdadm secondary ${DRBDRESOURCE}
;;
########################################################################
status)
exec 1>&3 2>&4
echo '[keepalived status]'
if [ -r /var/log/vrrp-status ]; then
tail -n 1 /var/log/vrrp-status | sed -e 's/^[ ]*//'
else
echo '/var/log/vrrp-status: no such file.'
fi
echo
echo '[DRBD]'
if [ -r /proc/drbd ]; then
cat /proc/drbd
else
echo 'maybe does not load drbd module.'
fi
exit 0
;;
########################################################################
restart)
/command/svc -t /service/vrrp.ds && sleep 3
;;
########################################################################
*)
exec 1>&3 2>&4
log '[ERROR] unknown argument'
echo "$0 {active|backup|restart|status}" 1>&2
exit 1
;;
esac
log 'END'
#! /bin/sh date '+%Y-%m-%d %H:%M:%S ' | tr -d '\n' >> /var/log/vrrp-status echo "$@" >> /var/log/vrrp-status
#!/bin/sh
[ -f /var/run/vrrp.pid ] && exit
exec 2>&1
trap 'kill -TERM $PID' TERM
trap 'kill -HUP $PID' HUP
trap 'kill -INT $PID' INT
envdir ./env softlimit -d3000000 -c0 \
/usr/local/sbin/keepalived \
-n --vrrp \
-f /usr/wd/etc/keepalived/ds.conf &
PID=$!
wait $PID
/usr/wd/sbin/dsadm backup
/mnt/drbd 10.10.31.0/255.255.255.0(rw,no_root_squash,async) 127.0.0.1(rw,no_root_squash,async)
local1.* /var/log/keepalived
keepalivedでのフェイルオーバを体験
設定ができたとろこでうまくフェイルオーバできるか確認してみましょう。
まずは図12のように、初期状態に戻します。これはds1とds2の両方で実行します。
続いて、ds1で図13のように実行します。図のように、DRBDのプライマリになって、仮想IPアドレス(10.10.31.20)が付与されていれば成功です。
ds1で成功したら、ds2でも同様に実行します。DRBDの状態が、Primary/UnknownからPrimary/Secondaryに変われば成功です。
では、クライアントマシンから、仮想IPアドレスをNFSマウントしてみます(図14)。マウントできたら、適当なファイルを作ってみます。
ではでは、フェイルオーバしてみましょう。現マスタであるds1のkeepalivedを再起動すれば、フェイルオーバが起こります(図15)。tail -f /var/log/keepalivedでログを確認しながら実行すると状況がわかりやすいでしょう。
うまくいけば、ds2がDRBDのプライマリになり、仮想IPアドレスもds2に移動しているはずです。
それでは、クライアントからみてフェイルオーバできているか確認してみます(図16)。あれ…エラーが出てしまいました。dfでみてもなんかどこかおかしそうです…
ds1# /usr/wd/sbin/dsadm backup ds1# /etc/init.d/drbd stop Stopping all DRBD resources. ds1# cat /proc/drbd cat: /proc/drbd: No such file or directory ←なくなっていればOK
ds1# /etc/init.d/drbd start
Starting DRBD resources: [ d0 s0 n0 ].
ds1# ln -s /usr/wd/daemon/vrrp.ds /service/vrrp.ds
ds1# /usr/wd/sbin/dsadm status
[keepalived status]
2007-05-02 06:37:37 INSTANCE ds MASTER 100
[DRBD]
version: 0.7.23 (api:79/proto:74)
SVN Revision: 2686 build by hirose@ds1, 2007-04-18 11:56:32
0: cs:WFConnection st:Primary/Unknown ld:Consistent
ns:0 nr:0 dw:5410 dr:168 al:11 bm:0 lo:0 pe:0 ua:0 ap:0
ds1# ip -4 addr show dev eth0
4: eth0: <BROADCAST,MULTICAST,UP,10000> mtu 1500 qdisc pfifo_fast qlen 1000
inet 10.10.31.21/16 brd 10.10.255.255 scope global eth0
inet 10.10.31.20/24 scope global eth0
cl01# mount -t nfs -o rw,soft,noac 10.10.31.20:/mnt/drbd /mnt/dss cl01# echo foo > /mnt/dss/foo cl01# echo bar > /mnt/dss/bar cl01# ls --full-time /mnt/dss total 8 -rw-rw-r-- 1 root root 4 2007-05-02 06:50:19.282073943 +0900 bar -rw-rw-r-- 1 root root 4 2007-05-02 06:50:13.129689443 +0900 foo
ds1# /command/svc -t /service/vrrp.ds
ds2# /usr/wd/sbin/dsadm status
[keepalived status]
2007-05-02 06:55:20 INSTANCE ds MASTER 100
[DRBD]
version: 0.7.23 (api:79/proto:74)
SVN Revision: 2686 build by hirose@ds1, 2007-04-18 11:56:32
0: cs:Connected st:Primary/Secondary ld:Consistent
ns:0 nr:5236 dw:5492 dr:63 al:2 bm:9 lo:0 pe:0 ua:0 ap:0
ds2# ip -4 addr show dev eth0
4: eth0: <BROADCAST,MULTICAST,UP,10000> mtu 1500 qdisc pfifo_fast qlen 1000
inet 10.10.31.22/16 brd 10.10.255.255 scope global eth0
inet 10.10.31.20/24 scope global eth0
cl01# ls --full-time /mnt/dss ls: /mnt/dss: Stale NFS file handle
フェイルオーバ時のNFS特有の問題点
IPレベルではちゃんとフェイルオーバしたように見えるのですが、どうしてクライアントからアクセスできなくなってしまったのでしょうか。その原因はNFSサーバにあります。
NFSサーバは、その状態情報をファイルに保存しています。Linuxの場合は、デフォルトで/var/lib/nfsの下のファイルにその情報が格納されます。
今回の件の原因は、exportしているファイルシステムや接続中のクライアントの情報などを管理する、xtabとrmtabというファイル(注8)です。クライアントは繋ぎっぱなしのつもりでも、フェイルオーバしてプライマリが変わった場合、これらのクライアント接続管理情報が引継がれないために、サーバから見ると接続したつもりのないクライアントからアクセスが来ているようにみえてしまうわけです。
この問題を解決するには2つの方法があります。
1つは、/var/lib/nfsも、DRBDを使ってミラーリングしてしまう方法です。例えば、/var/lib/nfsを/mnt/drbd/var/lib/nfsのシンボリックリンクにしてもよいですし、drbd.confに新たなresouceを追加して、これを/var/lib/nfsにマウントしてもよいです。いずれにしても、dsadmでこれらの処理を行えばよいでしょう。
もう1つは、kernel 2.6以降で使えるnfsdという仮想ファイルシステムをマウントする方法です(図17)。これをマウントすると、xtabやrmtabは使われなくなり、kernelのみが接続情報を知ることになります。また、(フェイルオーバ後に)未知のクライアントからのアクセスがあっても、kernelが善きに計らって処理してくれるようになります。これもdsadmで、NFSサーバを起動する前にマウントしてもよいですし、OS起動時に(セカンダリでも)マウントしてしまってもいよいです。
ちなみに、nfs-utils 1.0.7以降では、付属するinit.d/nfs-kernel-serverスクリプトの中で、マウントするようになっています。Debianの場合etch以降ならば特になにもしなくてもマウントしてくれるでしょう。
上記どちらかの対処をとることにより、フェイルオーバしても、クライアントからはまるでサーバがダウンなどせずにずっと正常に繋ぎっぱなしであるかのように見えるでしょう。
詳しくはman exportfsを参照してください。
# mount -t nfsd nfsd /proc/fs/nfs
おわりに
今回は、ハードウエア障害に強いストレージサーバを作ろうということで、
- DRBDによるミラーリング
- keepalivedによるフェイルオーバの自動化
- フェイルオーバ時に発生するNFS特有の問題点
といったトピックをお話ししました。
DRBD+keepalivedというベースの部分はそのままで、クライアントに対するインターフェースの部分をNFSからHTTPやほかのプロトコルに変える、という活用方法もあるのではないかと思います。
ただし、前半で触れたように、この構成は読み出しも書き込みもスケールしません。
スケールするには、今回紹介したようなストーレジサーバのセットを複数用意し、ユーザIDなどを元にパーティショニングする方法が考えられますが、全く別な構成も含めて、他にも何かよい方法がないか調査、実験中です。まだまだ紹介できるレベルにはなっていないので、とりあえずキーワードだけ列挙します。意見、耳より情報、アドバイスなどなど大歓迎ですので、私たちのブログ(注9)にコメントやトラックバックしていただけるとうれしいです!
- 電送方法
- iSCSI
- HyperSCSI
- AoE (ATA over Ethernet)
- 分散ファイルシステム
- Lustre
- GlusterFS
- Ceph
- 共有ディスクファイルシステム
- GFS
- OCFS2
今回のまとめ
- DRBDを使うと、ブロックデバイス単位のネットワーク越しのミラーリングができる。
- VRRPは、ルータやロードバランサ以外でもうまく使うと非常に有用。
コラム: 【ここだけの話の失敗談】DRBDでXFSを使う場合は…
ちょっと昔のkernel 2.6.11か2.6.12の頃の話ですが、DRBDのデバイスをXFSで使う場合、kernelのスタックサイズを4KBではなく8KBにしないと、ある日突然、サーバが何もいわずに落ちる問題がありました。(試した限りでは、bonnie++で負荷をかけ続けると、3日目ぐらいで落ちました)
最近のバージョンでは改善されているという情報もありますが、不意のダウンで困っている方は8KBに変更してみると効果があるかもしれません。
8KBにするには、make menuconfigの場合、Kernel hacking→Use 4Kb for kernel stacks instead of 8Kbのチェックを外してkernelをビルドしなおせばOKです。
この連載の記事一覧
参考図書
![[24時間365日] サーバ/インフラを支える技術 ‾スケーラビリティ、ハイパフォーマンス、省力運用 (WEB+DB PRESS plusシリーズ)](http://ecx.images-amazon.com/images/I/51uK4ACymiL._SL160_.jpg)
![[Web開発者のための]大規模サービス技術入門 ―データ構造、メモリ、OS、DB、サーバ/インフラ (WEB+DB PRESS plusシリーズ)](http://ecx.images-amazon.com/images/I/51GW5jxmdvL._SL160_.jpg)

目次
他コンテンツ
- home
- はじめに
- 書き物類
- はじめに
- スケーラブルWebシステム工房
- 現場指向のレプリケーション詳説 - mysql
- USBをシリアルコンソールに
- Debian woodyをkernel 2.6にするメモ
- kernelイメージから設定情報を取り出す
- AWStatsの検索文字列の文字化けを解消
- 現場指向のレプリケーション詳説 - mysql
- コード
- mregexp - MySQLで日本語の正規表現を扱う
- kcode - 各種文字コードを表示する

