注意
この文書は2007/12/22に書かれたもので、ソフトウエアの名称、バージョン、設定項目、社名などの固有名詞などなどは当時のまま掲載しています。
ですので、インストール手順や設定内容は最新版のドキュメントを参照していただき、この文書からは理論や考え方、構成のヒントなどを読み取っていただければと思います。
はじめに
前回のコラムでちょっと前フリをしましたが、今回はネットワークの冗長化のお話をしたいと思います。
今回取り上げるのはレイヤ2(注1)とその周辺がメインなので、ちょっととっつきづらいかもしれません。でも「落ちないサービス」を提供する上では避けては通れないトピックですので、本稿が読者のみなさんの助けになればいいなと思い今回もつづります。
さて今回の流れですが、まず前半で問題点の整理をして、後半は具体的なネットワーク構成を見ながらひとつひとつ問題を解決していきたいと思います。
問題の解決には、次にあげる技術を使用します。詳細は本文中で解説しますのでお楽しみに。
- Linuxのbonding device
- リンクアグリゲーション (IEEE 802.3ad)
- スパニングツリープロトコル (IEEE 802.1D, 802.1w)
OSI参照モデルにおける、第2層 - データリンク層を指します。具体的な実装でいうと、イーサネットやPPP、フレームリレーなどがこの層(レイヤ)に分類されます。 http://ja.wikipedia.org/wiki/OSI参照モデル http://en.wikipedia.org/wiki/OSI_model
こんなことで困ったことありませんか?
ケーススタディ:ネットワークが不通になる障害
筆者の実体験に基づいて、ネットワークが不通になる障害の事例をいくつかあげてみます。
(1)スイッチングハブのポートが壊れた
スイッチングハブ(以下、スイッチ)はハードディスクと違って可動部分がないので、滅多に壊れないという印象を持っているのではないでしょうか。
筆者も昔はそう思っていたのですが、個人的な経験を根拠にすると、スイッチのとあるポートのみ壊れるというケースは、思っていた以上によくあります。
当然ながら、ポートが壊れるとそのポートにつながっているマシンは通信不能になります。例えばこれが冗長化されていないDBサーバだったりするとかなり痛いです。
(2)スイッチがまるごと止った
スイッチがまるごと止まるなんてそうそうないのでは?と思うかもしれませんが、まちがってスイッチの電源ケーブルを抜いてしまったという人為的ミスをはじめ、全ポートリンクアップしたままなのにスイッチがハングアップしてしまい正常な通信ができなくなったという原因不明のケースまで、まるごと止まる可能性はないわけではありません。
ほかに、スイッチのファームウエアのバージョンアップや再起動など、意図的に停止したい場合もあります。
確かに、スイッチがまるごと止まる可能性は低いのですが、万が一止まった場合はスイッチに接続している全ての機器が不通になるので、その影響範囲は甚大です。
(3)ネットワークケーブルが抜けた
ネットワークケーブルがある日突然、断線したというのは個人的には経験ないのですが、まちがって抜いてしまったとか、カッチリはまってなくてちょっと引っ張ったら抜けてしまったといったケースは何度か経験したことがあります。
この場合の影響範囲は、スイッチのポートが壊れたときと同様、とあるマシンが通信不能になります。
問題点のまとめ
3つほど、ネットワークが不通になる障害事例をみてみました。
共通する特徴としては、物理的な要因が多く、頻度はそれほど高くないというのがあげられます。
一方、その影響は、故障する場所によっては致命的なものになる可能性があります。
例えば、いくらロードバランサでWebサーバを冗長化していてもロードバランサがつながっているスイッチのポートが壊れたらサービス停止ですし、ロードバランサを二重化していても、つながるスイッチがハングアップしてしまったら同じく停止してしまいます。
このように、発生頻度は低いものの、影響が大きくなる可能性をはらんでいるのが今回取り上げる、そしてこれから解決していくトピックの特徴です。
故障に強いネットワークを作る
問題点の整理ができたところで、早速ひとつひとつツブしていきましょう!
出発点
まずはシンプルなネットワーク構成からスタートしましょう。
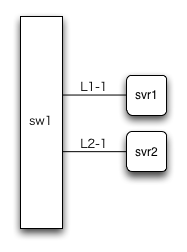
図1を見てください。先に整理した問題点と照らし合わせて考えると…
- × サーバsvr1がつながっているsw1のポートが壊れると不通
- × スイッチsw1が壊れると不通
- × ネットワークケーブルL1-1が抜けると不通
2本のケーブル
はじめの一歩として、2つの問題、
- × サーバsvr1がつながっているsw1のポートが壊れると不通
- × ネットワークケーブルL1-1が抜けると不通
を解消したいと思います。
どちらの場合も、もし、サーバとスイッチの間の接続が2本ならば解決します。例えば、サーバにNICを2つ搭載し、それぞれスイッチの異なったポートにつないでみると、図2のようになります。
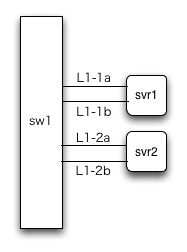
ただつないだだけでは故障時に自動的に切り替わってはくれませんので、ここでもう一捻り、Linuxのbonding deviceという機能を使います。
bonding deviceとは
bonding deviceとは、複数の物理的なNICを束ねて1つの擬似的なNICとして扱えるようにするものです。Linuxでは物理的なNICはeth0、eth1…というデバイス名になりますが、bonding deviceの名前はbond0となります。名前が異なる以外は、物理NICと同じように扱うことができます。
ここでは概略にとどめますので、bonding deviceについての詳しい説明や設定方法などは、以下のドキュメントを参照してください。
- Linux kernelソースに付属するもの linux-2.6.X.X/Documentation/networking/bonding.txt
- 『bonding機能紹介と展望』 http://osdn.jp/event/kernel2005/pdf/nec.png
とくに後者のPDFはとてもよくまとまっているので、bondingを扱う際には読んでおくべきです。
ところでbondingのメリットはなんでしょうか。それは耐障害性の向上と性能向上の2つです。
bondingのメリット(1) 耐障害性
表1のようにbondingにはいくつかのモードがあるのですが、どのモードを選んでも耐障害性が向上します。
bondingは束ねている物理NICを定期的に監視しています。もし監視に失敗した場合は、束ねているグループから自動的にそのNICを除外し、残りの物理NICを使って通信を行います。
監視の方法は2つあります。ARP(Address Resolution Protocol)監視とMII(Media Independent Interface)監視です。
ARP監視はターゲットとして指定したIPアドレス(複数指定可能)にARP要求を送信して、応答があるかないかを確認します。ターゲットのマシンがダウンすると、bondingは自分の物理NICが壊れたと誤判断してしまうので、ターゲットには落ちないマシンを複数指定することが求められます。
MII監視はハードウエア的なリンクアップの状態を監視します。ARP監視と違い監視ターゲットが不要なのと、ネットワーク上にパケットが流れないという利点があるのですが、万が一、スイッチがリンクアップしたままハングアップすると不通を検知できない危険性があります。
筆者らは、スイッチがリンクアップしたままハングアップしてしまい痛い思いをしたことがあるので、それ以来、ARP監視を使うようにしています。
bondingのメリット(2) 性能向上
bondingはモードによっては性能向上も期待できます。
具体的には、送信または受信に使用する物理NICを分散して使って性能向上を計ります。
モードによって分散方法やその特徴が大きく異なるので、詳しくは前述のドキュメントを参照してください。
| モード | 概説 |
|---|---|
| balance-rr | 送信時に使うNICを、ラウンドロビンで決定する |
| active-backup | アクティブ/バックアップ構成。送受信はアクティブデバイスだけで行う |
| balance-xor | 送信時に使うNICを、始点と宛先のMACアドレスのXORなどで決定する |
| broadcast | 全てのNICから送信する |
| 802.3ad | IEEE 802.3ad(リンクアグリゲーション)を使う |
| balance-tlb | NICの負荷状況をみて、送信時に使うNICを分散する |
| balance-alb | tlbに加え、受信時に使うNICも分散する |
今回使うモードは
今回は、ネットワークの冗長化がテーマなのと、数あるモードの中でも比較的扱いやすく動作も把握しやすいactive-backupモードを使います。
ふたつのスイッチ
bondingを使ったことで、2つの問題は解消できました。
- ○ サーバsvr1がつながっているsw1のポートが壊れると不通
- ○ ネットワークケーブルL1-1が抜けると不通
- × スイッチsw1が壊れると不通
残るはスイッチが壊れた場合です。というわけでスイッチをもう1台追加してみます。
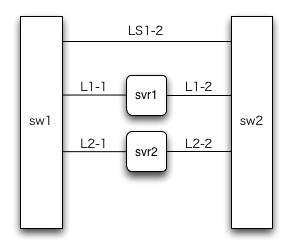
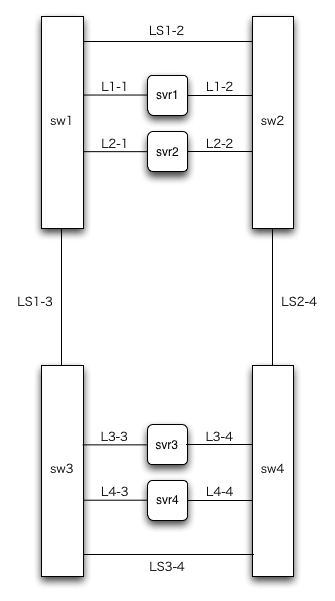
図3を見てください。
まず、bondingしている2つのNICからは、それぞれ別々のスイッチに接続します。ただここをつなげただけではスイッチsw1とsw2との間で通信できないのが問題になります。例えば、svr1はL1-1側が、svr2はL2-2側がbondingのアクティブになっている場合、svr1とsvr2は通信できません。そこで、図3のケーブルLS1-2のように、スイッチ間を接続します。
これでとりあえずはOKなのですが、スイッチ間接続の経路LS1-2がネットワークケーブル1本だけなのはちょっと心もとないです。なので、ここの経路はケーブル2本以上にしたいのですがただ単につなげてもダメなので、リンクアグリゲーションというものを使います。
リンクアグリゲーション(Link Aggregation)とは、IEEE 802.3adで標準化されている規格で、スイッチ間の複数の物理的な接続を擬似的に1本に束ねて扱うためのものです。bondingと似ていますね。リンクアグリゲーションを使うには、双方のスイッチがこれに対応しているのと、スイッチの設定作業が必要です。
リンクアグリゲーションを適用して、スイッチsw1とsw2の間の接続LS1-2を多重化しておけば、この経路のケーブルが1本抜けたり切れたりしても、ポートが1つ壊れても、何の問題もなく通信し続けられます。
さてさて、これで列挙した問題点は全てクリアできました。どこのケーブルが切れても、どこのスイッチがダウンしても、止まらないネットワークが手に入ったわけです。めでたしめでたし…
スイッチをふやしたい
しかーし。時は流れてサーバが増えて、スイッチのポートが足りなくなってきました。
ではではと、スイッチを増やしてみたのが図4です。
よーくこの図とにらめっこしてください。いくつか問題点がありますので。
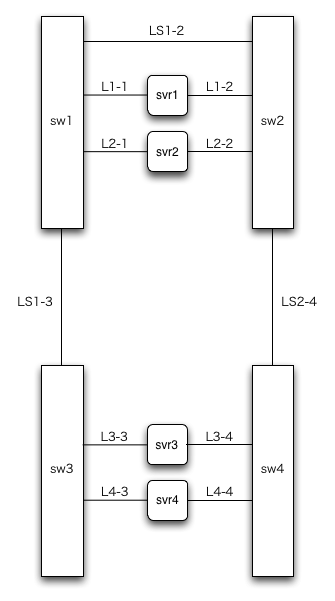
問題点(1) ケーブルLS1-3が切れたら?
まず1つめ。LS1-3のケーブルが切れた場合を考えてみましょう。ここの経路が断たれると、sw3は他のスイッチとつながる経路がなくなるので孤立してしまいます。このとき、svr3のbondingの監視がMIIで、かつ、L3-3側がbondingのアクティブだった場合、svr3からみればsw3へのリンクはアップしたままなのでbondingデバイスの切り替わりが起こりません。したがって、L3-3側がアクティブのままになってしまい、svr1やsvr2とは通信できなくなってしまいます。
これを解決するには2つ選択肢があります。
1つめは、bondingの監視をMIIではなくARP監視にした上で、ARP監視のターゲットをsvr1にすればOKです。そうすれば、LS1-3が切れた時点でL3-3からの経路ではsvr1と不通になるので、bondingのデバイスが切り替わりL3-4側がアクティブになり、疎通が回復します。
2つめは、前節でやったように、リンクアグリゲーションを使ってLS1-3の経路の耐障害性をあげる方法です。反対側のLS2-4の経路も同様にリンクアグリゲーションしましょう。
問題点(2) sw1が落ちたら?
つづいて問題点の2つめです。sw1が落ちた場合を考えてみましょう。
まず、svr1のbondingアクティブはL1-2に切り替わります。svr2も同様に切り替わります。ここまではOKです。bondingのおかげですてきにNICがフェイルオーバするはずです。
さてこのとき、もし、svr3のbondingアクティブがL3-3側だったらどうなるでしょうか。そうです。svr1とsvr3は通信できません。
この問題を解決するには、さっきと同じように、svr3のbondingの監視をARP監視にしてターゲットをsvr1にすればOKです。
この構成のまとめ
2つの問題とその解決方法をみてきました。
両方の解決方法に共通するのは「bondingの監視をARP監視にする」なので、この構成の場合はARP監視にすれば万事OKです。
ただ、ARP監視には監視ターゲットが必要です。監視ターゲットがダウンしたりアップしたりすると、それにつられてbondingデバイスもころころ切り替わってしまうので、監視ターゲットには堅牢なマシンを複数指定すべきという点に留意してください。
シカククつなげる
さきほどの構成はARP監視をすることによりめでたしめでたしとなったわけですが、ARP監視を使わない解決策をもうちょっと考えてみましょう。
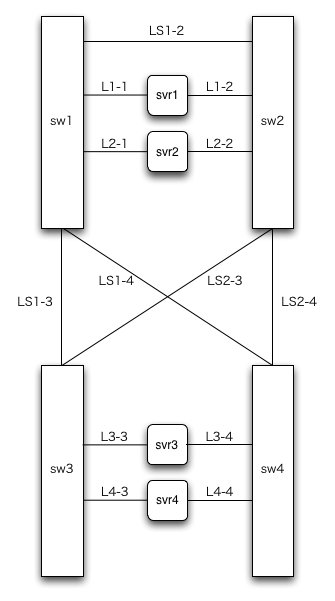
2つの問題点を振り返ってみると、sw3が離れ小島になってしまうのがいけないというところに帰結します。ならば離れ小島にならないようにと、sw3とsw4をつないでみたのが図5です、といきたいところなのですが、社内LANなどほかのネットワークにつながっている環境でお試しの読者の方はちょっとまってください。他のネットワークと接続していない隔離された環境でお試しの方はどうぞつないじゃってください。そしてブロードキャストアドレスにpingでも打ってみてください。どうでしょう。きっとスイッチのLEDがまばゆいばかりに光り輝いていることと思います。これがブロードキャストストームというやつです。とりあえず、LS3-4のケーブルを抜いてしばらくすれば収まるはずです。
ブロードキャストストームの恐怖
さて、ブロードキャストストームとは何か?
まず、ブロードキャストとは、特定の機器ではなく、ネットワーク上に存在する全ての機器にパケットを送るためのものです。例えば、svr1がブロードキャストを送信した場合をみてみましょう。L1-1がbondingのアクティブデバイスである場合、ブロードキャストパケットはsw1に到達します。sw1は(パケットが入ってきたポートを除いた)リンクアップしているポートすべて(つまりL2-1、LS1-3、LS1-2)にパケットを転送します。LS1-3に転送されたパケットに着目すると、sw3に到着し、sw3も同じように全てのポートに転送します。この調子で辿っていくと、[sw3]→(LS3-4)→[sw4]→(LS2-4)→[sw]2→(LS1-2)→[sw1]という旅路を経て、再びsw1に到着します。さてsw1は、このパケットはさっき自分が転送したものか、それとも別のマシンから送られてきたものか区別できないので、またLS1-3を経由してsw3に転送します。というわけで、パケットが延々とループしてしまいます。今はsw1を起点として左回りの流れをみましたが、右回りも同様です。
このようにブロードキャストパケットが永遠にぐるぐる回り続けることをブロードキャストストームといいます。ストームが発生すると、スイッチは全力でパケットを転送しまくるので、正常な通信の性能がおちたり、スイッチがダウンしてしまったりすることもあります。
救世主、スパニングツリー
ストームが発生する理由は、経路がループしている点にあります。しかし、経路の冗長化のためにはあえてループする配線にしたいこともあります。
そこで登場するのがスパニングツリープロトコル(以下、STP)です。
STPとは、ループした経路において、レイヤ2レベルでいくつかの経路を遮断してループを断ち切り、障害時には自動的に遮断を解除して経路を確保するためのものです。IEEE 802.1Dで規定されています。
さてこのSTPなのですが、経路が安定するまでにちょっと時間がかかります。STPの仕組み的に最大で50秒(注2)かかります。いったん安定すれば、故障が起きるなどトポロジの変化が発生しない限りは経路の再構成が走ることはないのですが、有事の際に1分近くネットワークが不通になるのは避けたいものです。特に、リモートで作業している場合に50秒間じっと待ち続けるのは不安との戦いです。STPの再構成のため一時的に不通になっているのか、別の問題で永続的に不通になっているのか区別がつかないですから。
というわけで、最大50秒の待ち時間を考えるとちょっと使いづらいSTPですが、その改良版のラピッドスパニングツリープロトコル(以下、RSTP)(注3)というものがあります。RSTPはSTPの改良版として考案されたものでSTPと互換性もあります。RSTPの一番の特徴は、"Rapid"という名のとおりSTPでは最大50秒かかった収束が、なんと数秒〜十数秒で収束する点です。
STP/RSTPはスイッチ間でのやりとりなので、構成するスイッチがSTP/RSTPに対応している必要があります。また、設定はスイッチで行えばよくて、スイッチにぶらさがっているサーバマシンなどではなんの設定をする必要もありません。
収束するまでに状態がいくつか遷移するのですが、そのタイマを合計すると50秒になります。 Max Age Timer+Forward Delay+Forward Delay=20+15+15=50
RSTPは元々IEEE 802.1wで標準化された規格なのですが、最近のIEEE 802.1D-2004ではSTPが削除されRSTPが後継として記載されています。
たすきがけにつなげる
最後にもうひとつだけネットワーク構成を紹介します。
さきほどのシカク構成の図5で、もし、LS1-3の経路が切れたとします。そうすると、svr1とsvr3の間の通信は最悪のケースでsvr1→[sw1]→(LS1-2)→[sw2]→(LS2-4)→[sw4]→(LS3-4)→[sw3]→svr3となります。これでも通信できるのでいいといえばいいのですが、全てのスイッチを経由するという点がちょっときもちわるいです。
そこでちょっと配線を変えたのが図6です。
LS3-4の経路をなくして、代わりに[sw1]→(LS1-4)→[sw4]と[sw2]→(LS203)→[sw3]の経路をつなぎました。たすきがけのような感じですね。
これだとsw4を経由しなくてもsw2とsw3が通信できるので、ちょっとだけですけどうれしいです。
ちなみにこの構成もループ構成なので、STP/RSTPを使う必要があるのは変わりません。
おわりに
止まらないネットワークを目指していくつかのネットワーク構成を紹介しました。
今回とりあげたようなレイヤ2周辺のトピックはちょっととっつきづらいと思いますし、そうそう故障するものでもないので、苦労して冗長構成にしなくてもいいかなぁと思うかもしれません。
しかし、いくら上位レイヤでデータのレプリケーションだのロードバランサだのがんばって冗長構成を組んでいても、その基礎土台となるレイヤ2のレベルで障害が発生すると、アッーという間に崩壊する危険性があります。
逆のいい方をすれば、盤石なレイヤ2があればこそ、安心して上位レイヤの構成を組むことができますし、安心して夜も眠れる、ということになります。
最近はインテリジェントスイッチの価格もだいぶ下がってきていますので、昔ほど金銭的コストをかけずとも、今回紹介した構成を実現することができます。安眠を手にいれたい方には是非、チャレンジして欲しいと思います。
今回のまとめ
- ネットワークの冗長化
- 冗長化技術の導入だけでなく、構成の工夫も必要
- 冗長化技術
- Linuxのbonding device
- リンクアグリゲーション (IEEE 802.3ad)
- スパニングツリープロトコル (IEEE 802.1D, 802.1w)
- 構成も工夫
- 2本のケーブル
- ふたつのスイッチ
- シカククつなげる
- たすきがけにつなげる
コラム: 実サービスの環境はこんな感じです
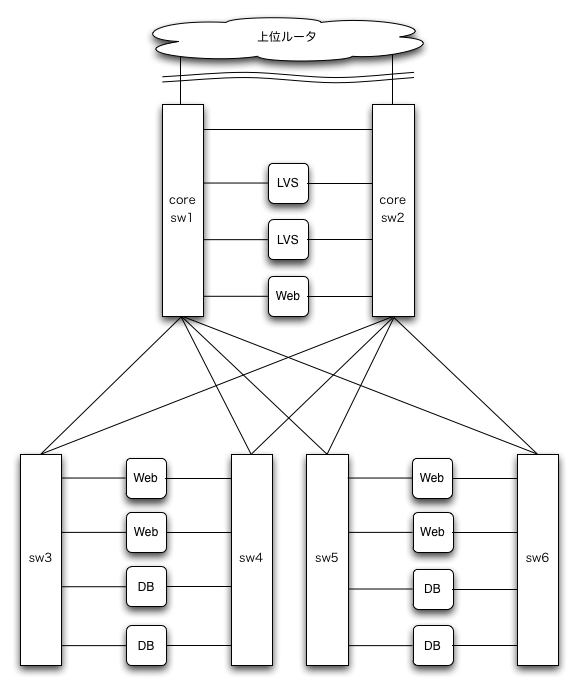
筆者らが手がけているネットワーク/サーバシステム(『DSAS』と呼んでいます)の構成は図7のようになっています。
基本的には本文最後に紹介した「たすきがけ」構成ですが、補足事項をあげてみます。
- sw1とsw2とをコアスイッチと呼んでいる
- インターネットへとつながる上位ルータは、コアスイッチとつながっている
- ちなみに、上位ルータはISPさんの管轄で、VRRPで冗長化してもらっていて、物理配線も2本(それぞれsw1とsw2へ)ひいてもらっている
- スイッチを増設する際は、コアスイッチを中心とするようなスター型にしている
- 図では、sw3とsw4のセットとsw5とsw6のセットを、それぞれコアスイッチとたすきがけで接続している
- bondingの監視はARP監視で
- ARP監視ターゲットとして、IPアドレスを2つ指定している
- このIPアドレスは、外部用ロードバランサと内部用ロードバランサ
- それぞれVRRPで冗長化している仮想IPアドレスなので、合計4台のマシンが同時にダウンしない限り、bondingの切り替えは発生しないことになる
- RSTPのプライオリティは、sw1を1、sw2を2、そのほかのスイッチを8(注4)として設定し、スター型の中心でもあり対外線との接続でもあるコアスイッチ(sw1、sw2)のどちらかがかならずルートブリッジになるようにしている
- ルートブリッジとは、STP/RSTPが構成するツリー構造の根(ルート)となるスイッチのこと
- ちょっと乱暴ないいかたですが、ルートブリッジのポートはSTP/RSTPによってブロックされることはありません
便宜的にプライオリティを1、2、8と書きましたが、STPのプライオリティの値は4096の倍数と決まっているので、実際の値はそれぞれ4096(1×4096)、8192(2×4096)、32768(8×4096)となります。
この連載の記事一覧
参考図書
![[24時間365日] サーバ/インフラを支える技術 ‾スケーラビリティ、ハイパフォーマンス、省力運用 (WEB+DB PRESS plusシリーズ)](http://ecx.images-amazon.com/images/I/51uK4ACymiL._SL160_.jpg)
![[Web開発者のための]大規模サービス技術入門 ―データ構造、メモリ、OS、DB、サーバ/インフラ (WEB+DB PRESS plusシリーズ)](http://ecx.images-amazon.com/images/I/51GW5jxmdvL._SL160_.jpg)

目次
他コンテンツ
- home
- はじめに
- 書き物類
- はじめに
- スケーラブルWebシステム工房
- 現場指向のレプリケーション詳説 - mysql
- USBをシリアルコンソールに
- Debian woodyをkernel 2.6にするメモ
- kernelイメージから設定情報を取り出す
- AWStatsの検索文字列の文字化けを解消
- 現場指向のレプリケーション詳説 - mysql
- コード
- mregexp - MySQLで日本語の正規表現を扱う
- kcode - 各種文字コードを表示する


{kind=link}